2023. 7. 31. 17:35ㆍ개발/Deep Learning
최근 chatGPT가 이전 모델에 비해 엄청난 발전을 이루면서 다양한 분야로 많이 발전했다.
지금까지 어떻게 발전해 왔는지 알아보고 지금은 어떤 방향으로 발전하고 있는지 조사한 결과다.
챗봇의 시작

1950년 Turing Test
튜링테스트는 인간이 기계와 대화하고 있다는 사실을 깨닫지 못한 채로 5분 동안 대화한다면 튜링 테스트를 통과한것으로 본다. 즉, 사람이 인지 하지 못할 정도의 지능을 가졌는지 판별하는 테스트입니다.
앨런 튜링은 기계가 인간의 생각을 모방할 수 있는지를 판별하기 위한 시험을 만들고 이를 통해 기계의 수준을 판별할 수 있도록 만들었습니다.
과정은 아래 그림처럼 진행하게 됩니다. 각각 격리된 방에서 진짜 사람과 컴퓨터는 시험관과 대화를 하게되고, 시험관은 어느쪽인 컴퓨터인지 둘다 사람인지를 맞추는 과정을 진행하게됩니다. 이 때 시험관이 컴퓨터를 맞추지 못한다면 이 기계는 인간을 모방하여 대화할 수 있음을 뜻합니다.

오래전에 나온 방법인 만큼 개인적으로는 시험관의 질문 수준에 따라 견해차이가 있을것이라고 보이고 당시에는 지금과 같은 인공지능이 없었기 때문에 튜링테스트를 통과하는 것은 어려울 뿐더라 하나의 테스트로는 판단하기 힘들었으리라 보인다.
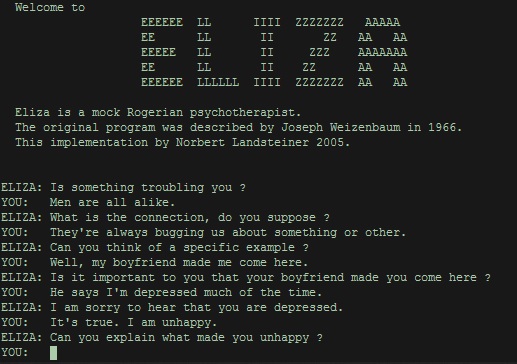
1966년 ELIZA
초기의 자연어 처리 알고리즘으로 MIT에서 개발되었다. 간단한 패턴 매칭을 사용한 것으로 SW 개발자 관점에서 보면 문자열 검색 알고리즘의 일종을 사용해서 이미 하드코딩되어 있는 정해진 문제와 답변 리스트중 가장 유사한 문제를 찾아 답변해주는 방식이다. 알고리즘의 특성상 아주 근사한 답변을 내놓기도 하지만 아주 다른 결과를 내놓기도 한다.
그 당시 많은 데이터를 넣어놨었는지 일부 사용자는 프로그램임을 알아차리지 못하여 튜링 테스트를 통과한 최초의 프로그램으로 알려져있다.
코드 : https://github.com/wadetb/eliza 를 살펴보면 하드코딩되어 패턴매칭을 통해 구현할 수 있음을 확인할수있다.
1972년 Parry
ELIZA와 비슷하게 생성했으며, 정신분열증 환자를 모방한 모델로 의사들이 Parry와 대화를 하고 어떤것이 진짜 정신분열증 환자인지를 맞출 수 있도록 튜링 테스트를 진행했었는데 이때 48%만이 진짜 정신분열증 환자를 맞출 수 있었습니다.
1983 Racter
Racter는 영어 산문을 무작위로 생성하는 프로그램입니다. Mindscape를 통해 출시된 것이 아닌 확장된 버전의 소프트웨어가 출판된 책 "The Police's Beard Is Half Constructed"의 텍스트를 생성하는 데 사용되었습니다.
1995 A.L.I.C.E
A.L.I.C.E는 Artificial Linguistic Internet Computer Entity의 줄임말로 AIML(Artificial Intelligence Markup Language)이라는 XML 기반 스크립트로 패턴과 탬플릿이 구성되어있습니다. 패턴에 있는 문장이 입력되면 탬플릿에 있는 답변을 출력하는 형식입니다.
그래서 A.L.I.C.E는 튜링테스트와 비슷한 기조를 가진 Loebner Prize라는 챗봇 대회에서 2000년과 2001년에 수상을 했다고 합니다.
https://www.pandorabots.com/pandora/talk?botid=b8d616e35e36e881 에서 직접 테스트해볼 수 있습니다.
2005 Jabberwacky
이 봇의 목적은 "흥미롭고 재밌고 유머스러운 방식으로 자연스러운 인간 대화를 시뮬레이트하는 것"이다.
http://www.jabberwacky.com/ 에서 직접 테스트해 볼 수 있습니다.
2014 slack bot
모두가 다아는 slack 메신저를 이용하여 chatbot을 만들수 있는 기능이다. 이를 통해 사용자는 원하는 조건에 따라 응답할 수 있도록 구성할 수 있다. AI방식은 아니지만 사용자가 구성을 많이 해둘수록 다양한 방법으로 서비스를 제공할 수 있다.
Transformer 의 등장
트랜스포머(Transformer)는 2017년 구글이 발표한 논문인 "Attention is all you need"에서 나온 모델로 기존의 seq2seq의 구조인 인코더-디코더를 따르면서도, 논문의 이름처럼 어텐션(Attention)만으로 구현한 모델이며, 이 모델은 RNN을 사용하지 않고, 인코더-디코더 구조를 설계하였음에도 번역 성능에서도 RNN보다 우수한 성능을 보여주었다.
이 것이 chatGPT로 발전하기 위한 첫걸음이라고 볼 수 있다.
LLM (Large Language Models)
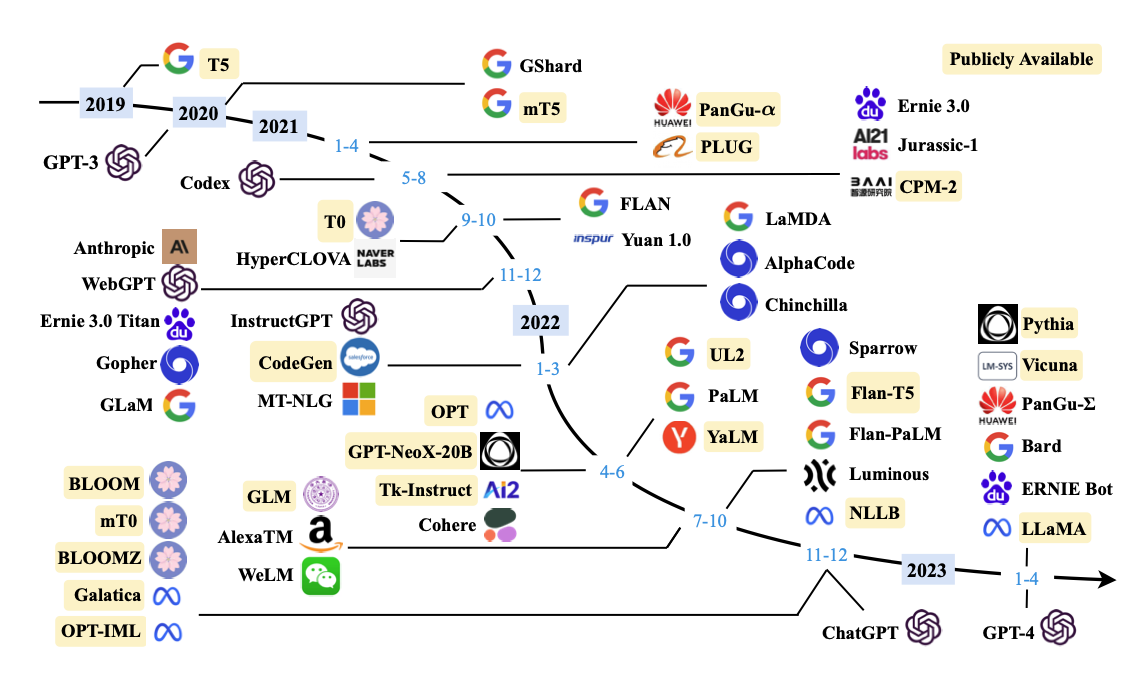
모든 딥러닝 모델들은 학습데이터의 양과 품질에 따라 성능이 좌지우지된다. 자연어의 경우에는 많은 데이터를 학습함으로써 더 정교한 성능을 기대할수있게 되므로 많은 데이터를 사용하는 시도가 이루어졌다.
큰 언어 모델(Large Language Models)은 막대한 양의 데이터와 컴퓨팅 자원을 이용하여 훈련된 자연어 처리(Natural Language Processing, NLP) 모델을 가리킵니다. 이러한 모델은 인공지능 분야의 한 분야인 기계 학습과 딥 러닝 기술을 기반으로 구축된다.
기본적으로 큰 언어 모델은 매우 많은 양의 텍스트 데이터를 입력으로 받아들이고, 문법, 의미, 문맥 등 자연어의 다양한 측면을 이해하고 분석하는 데 사용됩니다. 큰 언어 모델은 일반적으로 다양한 언어에 적용 가능하며, 읽기, 쓰기, 이해, 질의응답, 번역, 감정 분석 등과 같은 다양한 자연어 처리 작업을 수행할 수 있다.
대표적인 큰 언어 모델로는 OpenAI에서 개발한 GPT (Generative Pre-trained Transformer) 시리즈가 있다. GPT 모델은 트랜스포머(Transformer)라고 불리는 딥 러닝 아키텍처를 기반으로 하며, 이전의 작업에서 학습된 많은 데이터를 사용하여 자연어 이해 능력을 강화하는 사전 훈련 단계를 거친다. GPT-3는 특히 엄청난 규모의 모델로, 1750억 개 이상의 파라미터를 가지고 있으며, 대량의 텍스트 데이터로 사전 훈련되었다.
큰 언어 모델은 다양한 응용 분야에 사용되고 있다. 예를 들어, 자연어 질의응답 시스템에서는 사용자가 질문을 주면 모델이 해당 질문을 이해하고 정확한 답변을 생성할 수 있다. 또한 대화형 AI 챗봇, 자동 문서 요약, 언어 번역, 자연어 생성, 감성 분석 등 다양한 NLP 작업에 활용된다.
딥러닝의 많은 논문은 결과를 증명하기 위해 코드로 재현할 수 있게 해두며, 오픈소스로 운영되는 곳이 많다. 하지만 몇몇 회사에서 제안된 내용들은 비공개인 경우도 꽤있다. 그 중 openAI와 Google 에서 LLM도 대표적이다. 그래서 사람들은 이런 문화를 피하고 싶었던 것인지 chatGPT 같은 모델보다 훨씬 경량화 되었지만 성능은 뒤쳐지지 않는 모델을 오픈소스로 내놓고 있다.
2023년 6월 27일기준으로 23개의 오픈모델이 공개되었으며, '팰컨'의 경우 허깅페이스의 LLM 성능평가 순위에서 1위를 차지했다고 한다.
관련 내용 : https://huggingface.co/tiiuae/falcon-40b
tiiuae/falcon-40b · Hugging Face
🚀 Falcon-40B Falcon-40B is a 40B parameters causal decoder-only model built by TII and trained on 1,000B tokens of RefinedWeb enhanced with curated corpora. It is made available under the Apache 2.0 license. Paper coming soon 😊. Call for Proposals :
huggingface.co